Qwen has just announced his latest open-source Qwen3-VL embedding and reranker models with state-of-the-art multimodal embedding and reranking.
They support text, images, screenshots, videos, and mixed-modal inputs for advanced information retrieval and cross-modal understanding.
A total of four models are released by Qwen under the Qwen3-VL series with multimodal capability with best-in-class performance for visual and video understanding tasks.
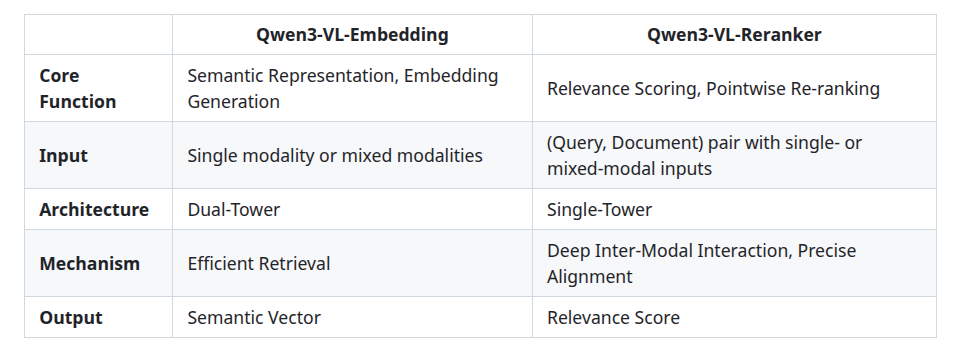
These models can be categorized into two categories:
- Embedding Models: Converts input data (text, images, video) into numerical vectors that capture semantic meaning.
- Reranker Models: take candidate pairs (e.g., a query and documents) and score their relevance score.
Features of Qwen3-VL models
- Multimodal Versatility: These models can seamlessly process inputs containing text, images, screenshots, and video within a unified framework.
- Unified Representation Space: They generate semantically rich vectors that capture visual and textual information in a shared space, facilitating efficient retrieval across different modalities
- High-Precision Reranking: The reranking model accepts input pairs where both can consist of arbitrary single or mixed modalities—and outputs precise relevance scores for retrieval accuracy.
- Multilanguage: These models support over 30 languages, ideal for global applications.
Architectures of Qwen3-VL Models
Qwen3-VL Embedding: Dual-Tower Architecture
The dual tower architecture, also known as two-tower architecture, has separate neural networks, referred to as “towers”, that efficiently encode any input into vectors.
They receive single-modal or mixed-modal input and map it into a high-dimensional semantic vector.
Qwen3-VL-Reranker: Single-Tower Architecture
They treat a user’s query and a document as a single, combined input and process them together to deeply understand their relationship and calculate a highly accurate relevance score
Utilizes a cross-attention mechanism for deeper, finer-grained intermodal interaction and information fusion
Model Evaluations
The Qwen3-VL-Embedding-8B model achieves state-of-the-art results on MMEB-V2, surpassing all previous open-source models.
If we break down the performance across different retrieval modalities, these models consistently achieve high-quality results on image, visual document, and video retrieval subtasks.
Limitations
While Qwen3-VL Models offers strong multimodal capabilities, there are some general limitations that we should know before beginning to use it.
One of the major challenges is high computational power. These models, especially the larger 8B variants, need powerful GPUs with sufficient memory to operate.
Running them on CPUs or low-resource machines will be extremely difficult and can lead to low performance.
Another limitation is large model size. Downloading and storing these models requires significant disk space and memory. This can increase infrastructure costs, particularly in cloud environments.
Conclusion
Qwen3-VL-Embedding shows how far multimodal AI has come. Instead of treating text, images, and videos as separate data types, it brings them together in one shared understanding space.
As a result, this makes searching, matching, and ranking information much more accurate and useful in real-world applications.
Moreover, with support for multiple languages, flexible embedding sizes, and open-source availability, it fits well into modern artificial intelligence systems.
For teams building semantic search, multimodal RAG pipelines, or intelligent product search, Qwen3-VL-Embedding offers a reliable foundation.

Be the first to comment.