NVIDIA recently announced Nemotron 3 Super. It is an open-source AI model that helps AI agents work better and faster.
It was released on March 11, 2026.
The model uses a new design that helps it reason better while using much less computing power, even for long tasks and multi-agent systems.
Why Agentic Reasoning Needs a New Approach
Today’s AI agents do many tasks, like writing code, checking security issues, studying finance data, or planning actions. But they still face two big problems.
Careful reasoning needs many steps. These steps use more computing power and make the process slower and more costly.
Context explosion: AI agents must track long histories, such as code, logs, or long chats.
Transformer-based dense models are difficult to use as it is quadratic in attention cost and its memory requirements are high.
Mixture of Experts (MoE) models can save resources, but they still slow down when working with very long inputs.
These issues are directly addressed in Nemotron 3 Super. It is based on Nemotron 3 Nano (released late 2025) but is scaled to higher techniques.
Core Architecture: Hybrid Mamba-Transformer MoE
In its simplest form, Nemotron 3 Super is based on a hybrid Mamba-Transformer Mixture-of-Experts:
They update their state very fast and handle longer inputs well. This helps when tasks have long context and memory use grows too much.
Transformer attention is used only when needed. It helps the model understand connections and think more clearly.
The mix is interspersed with layers of MoE to maintain active computation low.
This mixed model is faster than regular Transformer models, especially when it creates long answers for AI agents.
Major Innovations in Nemotron 3 Super
1. LatentMoE: A routing method that groups tokens into larger units and then sends them to the right experts.
Compared to normal MoE routers, this model can use about four times more experts with almost the same cost. This helps it give better results.
2. Multi-Token Prediction (MTP): This lets the model predict many tokens at once. It helps the model respond faster and learn better during training.
3. NVFP4 Pre-training: This uses a 4-bit format from NVIDIA. It needs less memory and helps the model train faster.
4. 1M-token context window: The model can handle very long inputs. This helps AI agents remember more and follow long tasks step by step.
Scale and Efficiency Numbers
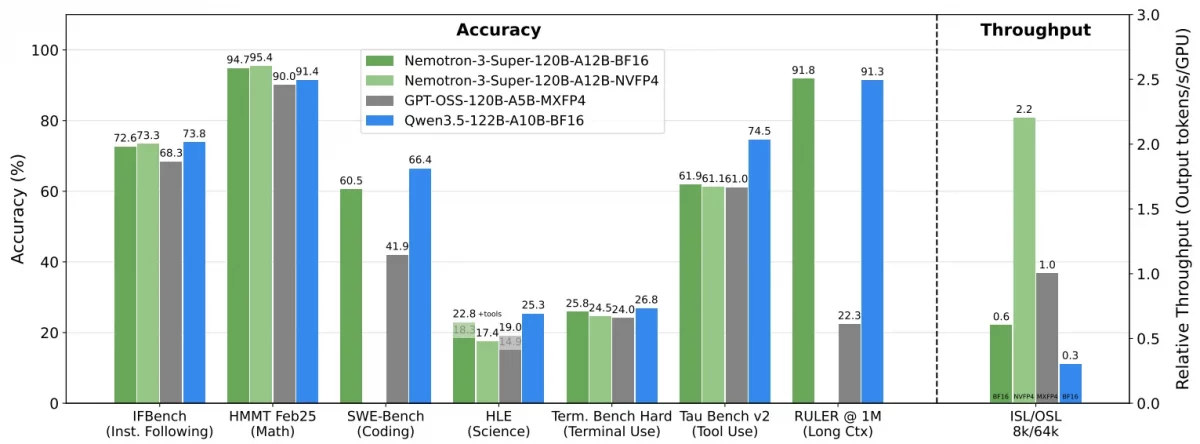
Image Source : nemotron-3-super@nvidia-blogs
- Total parameters: 120 billion (120.6B with some reports)
- Parameters per forward pass: Active: Approximately 12 billion (12.7B in certain tests).
- Context length: To 1 million tokens.
- Throughput gains: It runs much faster than older models. It is about 5× faster than past Nemotron Super models, 2.2× faster than GPT-OSS-120B, and about 7.5× faster than Qwen3.5-122B for long tasks.
The model performs very well in reasoning, coding, math, and agent tasks. It also works much faster than many other models.
Data Highlights and Training of Nemotron 3 Super
Super pre-trains similarly to its smaller brother on approximately 25 trillion tokens in 2 stages:
- Phase 1 (80 percent): Wide scope and coverage.
- Phase 2 (20 percent): Quality data revolving around benchmark accuracy and agency competence.
Agent skills are improved during post-training using large reinforcement learning setups.
On Hugging Face, NVIDIA also shared special training data, including synthetic code examples.
Availability and Openness of Nemotron 3 Super
As NVIDIA believes in open AI, Nemotron 3 Super is open:
- Weights (base, post-trained, quantized versions such as FP8, BF16, NVFP4)
- Training datasets and recipes
- Availably on Hugging (e.g. nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-FP8)
Also supported on NVIDIA inference platforms, Together, Perplexity, OpenRouter, and plenty of cloud providers (Google Vertex AI, Oracle, soon AWS Bedrock, Azure, etc.).
Developers can fine-tune it, compress it, or run it on their own systems. This is helpful for private or secure business use.
Conclusion
Nemotron-3 Super shows a shift toward smarter and more efficient Artifical Intelligence models, instead of just making bigger ones. The next model, Nemotron-3 Ultra, will be even larger.
It combines Mamba’s speed, smart routing from LatentMoE, and a very large context. This helps AI agents work well on real hardware, even on one GPU or small clusters.
You can try this model now if you build AI agents for coding, security checks, research help, or managing many agents.
It gives strong results while using very little power. This means people can build powerful AI without huge GPU farms.
Want to Build AI-powered solutions visit Webkul!

Be the first to comment.