
The art of creating images through the use of Artificial Intellignece has significantly improved over the past few years, due to something known as diffusion models.
These tools are very effective in creating realistic images, cool textures, lighting and artistry.
But they often mess up when you need exact text in the image, follow tricky instructions, or include facts that require real knowledge.
The images may be good but they do not necessarily depict what you intended to see.
GLM-Image comes in at that. First open-source model made for real use that mixes auto-regressive modeling with diffusion decoding.
The Main Idea Behind It
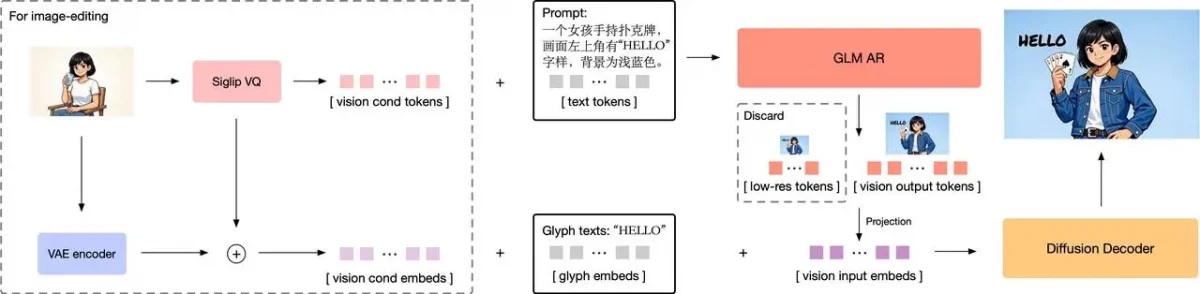
Image source: GLM-Image @zai-org (GitHub) — Apache-2.0 license
In the simplest sense, GLM-Image is of the opinion that, determining what image represents, and making it look good is not the same thing.
This should be addressed using different tools.
1) Auto-regressive models
- Auto-regressive models are just like big language AIs, except that they generate one thing at a time.
- This makes them reason, obey and ensure that nothing does not go wrong.
2) Diffussion models
- Diffusion models are excellent at completing the visuals, but poor at planning or reasoning.
GLM-Image assembles these together.
The auto-regressive part decides what’s in the picture, and the diffusion part decides how it looks.
In this manner, the outcomes are correct as well as beautiful.
How It All Works
GLM-Image consists of two major components, which collaborate.
The former is an auto-regressive generator, which is an instance of a GLM-4-9B, 9 billion parameters language model.
This section reads your prompt, cogitates about objects and their interrelations, makes plans of the layout and any text.
The second one is a CogView4 diffusion decoder, trained on a Diffusion Transformer (DiT) with 7 billion parameters
It simply involves making the picture-with textures and lights and hard edges and minute details.
You can imagine it in this way: the planner is the auto-regressive model, and the artist is the one who captures the plan into life, the diffusion model.
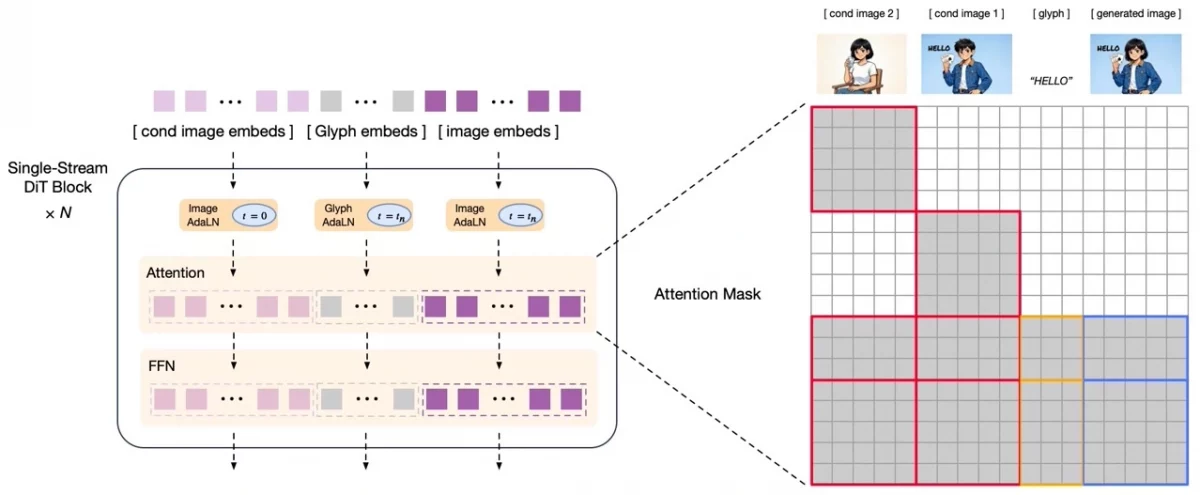
Image source: GLM-Image @zai-org (GitHub) — Apache-2.0 license
Why This Hybrid Approach Matters
Conventional diffusion models begin with random noise and enhance it to an image.
This gives nice visual effects but does not have good argument thus they often confuse text, layout or detailed prompts.
GLM-Image divides the work wisely:
An auto-regressive model (like smart language AI) first reads the prompt, plans the picture, puts objects in place, and works with text or facts.
A diffusion decoder then adds the fine visual details, textures, and polish.
With this division, it offers the best of both worlds, intelligent planning and breath-taking quality.
Why Pure Diffusion Models Have Trouble
Diffusion models The models begin with random noise and gradually refine it to form an image.
This is good in quality, but not in thinking and taking steps.
So, they often fail at:
- Easy-to-read printed text in the picture.
- Managing long or lengthy requests.
- Keeping facts straight
The more recent models that can work well with text are more like auto-regressive ones. GLM-Image goes even a step further and incorporates reasoning into the equation.
Turning Images into Tokens
The system breaks images into visual tokens, enabling AI to understand and reason about them like words in a sentence.
These tokens can be made in various forms. Others store a great amount of visual data and are difficult to operate.
There are those who concentrate on the meaning and forget about details.
GLM-Image involves semantic-VQ tokens that represent objects, layouts, structures.
They are generated using the XOmni tokenizer, which links them to true meaning.
This helps the auto-regressive model build things step by step and lets training run smoothly.
How the Auto-Regressive Part Learns
This section begins at GLM-4-9B which is already language-smart.
The text-handling layer is maintained constant during training to ensure that that skill is maintained.
A new layer introduces the vision tokens, and the model processes images instead of words.
It combines text and images using MRoPE positional encoding, which helps keep things in the right place
This is important in making or adding text to images.
Training at Different Sizes and Step-by-Step Building
GLM-Image is trained on the different image sizes, small and larger.
The system reduces images by 16 times in space to keep the token lists small
In the case of big images, simply moving left and right would produce untidy layouts.
Thus, it is based on progressive generation: initially create some low-res tokens to assemble the basic model and add details afterward.
This brings big images to be more orderly and manageable.
The Diffusion Decoder Setup
The decoder uses those meaning-packed tokens and converts them to a complete picture.
It has one-stream Diffusion Transformer that is trained with flow matching, which is a superior, quicker approach than the ancient diffusion techniques.
These tokens mix with VAE latents (coded bits of images in diffusion).
The system doesn’t need an extra text encoder because the tokens already have the smarts, which saves time and memory.
Better Text in Images Using Glyphs
It is extremely difficult to have clear text in an image, such as Chinese characters. GLM Image corrects this using a straight forward Glyph-byT5 model.
It codes letters in the form of the shapes. The embeddings are added to visual tokens in such a way that the decoder can produce sharp and right text.
Editing Images and Keeping Details
In editing, you would like to retain information of the original.l.
Just semantic tokens are not sufficient.
GLM-Image connects the decoder to the tokens as well as the VAE latents of the original.
It uses block-causal attention to reuse parts smartly, keeping details while staying fast
Fine-Tuning with Separate Rewards
GLM-Image gets better using reinforcement learning, but each part gets its own focus.
The auto-regressive side is better in meaning, appearances and text accuracy.
Diffusion side enhances images, textures and precise text.
This division makes both parties robust without confronting each other.
Conclusion
GLM-Image alters our perception of AI image tools. It does not perceive images as noise to correct; it perceives images as info to interpret.
It makes image AI think more like a smart language model and keeps images looking great by breaking down how it understands and creates them.”
Such a combination of auto-regressive and diffusion may result in future models that are creative, precise, readable, and reliable.
“To get the latest AI updates and Advancements, visit Webkul !”

Be the first to comment.