Running big AI models is getting ridiculously expensive.
Bigger models use more memory and power, especially for long chats or large searches.
Google Research just dropped something promising called TurboQuant.
For a long time, quantization has been the default trick to make large language models smaller, faster, and cheaper.
If you’ve worked with LLMs, you’ve probably used int8 or int4 models to fit things into limited GPU memory.
But recently, Google Research introduced TurboQuant, and it changes the game in a subtle but important way.
Instead of compressing the model, it compresses something even more critical during runtime, the KV cache.
This shift is important because the bottleneck in modern LLMs is no longer just model size. It’s inference memory and speed, especially when dealing with long contexts.
The Real Problem It Solves
Modern AI models (like the ones powering chatbots, recommendation engines, or search) rely heavily on vectors.
A long lists of numbers that represent words, images, products, or user queries.
These vectors live in something called the KV cache (key-value cache).
Which keeps track of previous calculations so the model doesn’t have to redo them every time.
As conversations get longer or you search through huge databases, this cache explodes in size, eating up tons of expensive GPU memory.
As more tokens are processed:
• KV cache keeps growing linearly
• Memory usage increases rapidly
• Attention computation becomes slower
This becomes a serious issue in long conversations, RAG systems, and agent workflows. And here’s the key point: Quantization does not solve this problem.
TurboQuant tackles exactly this by intelligently compressing these vectors.
How TurboQuant Actually Works
It uses two clever tricks together:
1. The main compression step – PolarQuant
Instead of storing vectors in regular Cartesian coordinates (x, y, z…), it converts them into polar coordinates.
It basically radius (how strong the signal is) and angle (which direction it points).
Example :
Instead of saying “walk 3 steps east and 4 steps north”, you just say “walk 5 steps at a 53° angle”.
It’s more compact and structured, so it’s much easier to compress.
2. The cleanup step – Quantized Johnson-Lindenstrauss (QJL)
After PolarQuant, there are still some tiny errors.
QJL fixes them by reducing each remaining number to just one bit — either +1 or -1 .
while cleverly preserving the important relationships between vectors.
Together, these two steps let TurboQuant compress vectors extremely well without destroying their meaning.
TurboQuant vs Quantization
Here’s the clean comparison:
- Quantization optimizes model weights, while TurboQuant optimizes the KV cache during inference.
- Quantization is applied before or after training, TurboQuant works in real time during inference.
- Quantization has limited impact on long context, TurboQuant has significant impact.
Real-World Impact
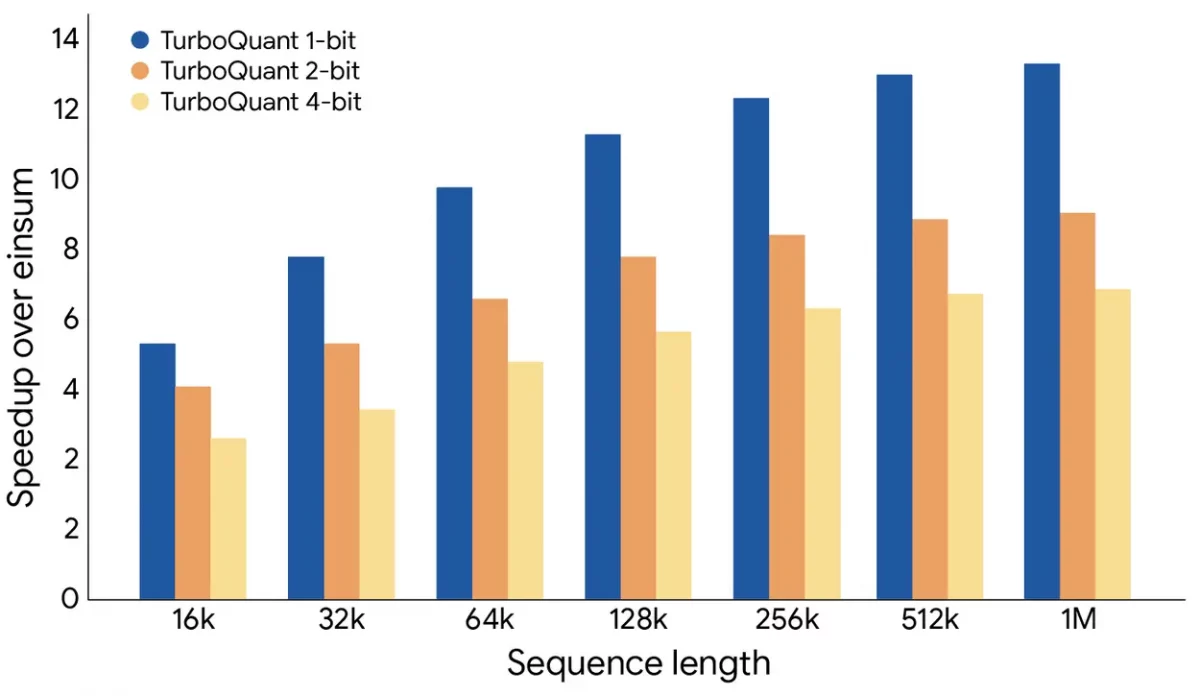
– Memory savings: From 32 bits per number down to just 3–4 bits → roughly 6x smaller memory footprint.
– Speed boost: Attention calculations (a major bottleneck) can become up to 8x faster.
– No need to retrain the model.
– Chatbots can handle much longer conversations without running out of memory.
– Recommendation and search systems can store many more items at a lower cost.
This means:
– Chatbots can handle much longer conversations without running out of memory.
– AI agents with memory
Recommendation and search systems can store many more items at a lower cost and still give fast, accurate results.
Why This Matters
We’ve been obsessed with making AI models bigger and bigger.
TurboQuant reminds us that smarter compression can be just as powerful as throwing more GPUs at the problem.
It makes Artificial Intelligence cheaper, easier to use, and easier to run, even without big GPU systems.
In short:
TurboQuant is like learning how to pack a suitcase like a pro. You fit way more stuff in, nothing important gets left behind, and it becomes much easier to carry around.
This kind of optimization might be exactly what we need for the next phase of practical, everyday AI.
Want to Build AI-powered solutions visit Webkul!

Be the first to comment.