DeepSeek-OCR 2 is also recent model that switches the way OCR models read intricate documents.
The majority of OCR systems have a mechanical approach, scanning a page as a printer:
- Beginning at the upper-left hand corner.
- Moving left to right
- Then onward still maintaining line by line.
This is true of simple paragraphs, but actual documents are not usually that simple.
Humans don’t read like that.
Also OCR combined with AI in tools like Invoice Data Extraction goods but not feel naturally .
Natural process: When we visit a page we automatically:
- Notice headings first
- Jump between sections
- Pay attention to tables or formulas individually.
- Follow meaning not pixel order.Vision Tokenizer: Yet Effective
DeepSeek-OCR 2 poses a significant question:
Is it possible to use OCR to learn to read semantically without scanning it in a fixed grid .
The DeepSeek-OCR 2 paper answers this question with a resounding yes.
The most important innovation is DeepEncoder V2.
It shows the model how to read by organizing the information clearly.
Why Traditional OCR tends to fail with real documents
OCR encoders today continue to use raster-type scanning.
They split the image into small parts and send them into the model.
That approach works for:
- Plain text blocks
- Simple layouts
However, it has serious problems with documents such as:
- Multi‑column articles
- Tables and spreadsheets
- Mathematical expressions
- Articles, periodicals, journals.
Turning a 2D layout into a 1D line often loses the original reading order.
DeepSeek-OCR 2: Higher-Level Architecture
The general OCR pipeline is also comparable with the initial DeepSeek-OCR:
Image → Encoder → LLM Decoder → Text Output
The significant upgrade is totally within the encoder:
Past version utilized DeepEncoder.
DeepSeek-OCR 2 is based on DeepEncoder V2.
The decoder (the 3B MoE language model) remains largely the same.
It reads the content in a meaningful order, which makes it easier and more accurate.
DeepEncoder V2: Teaching the Model to Read
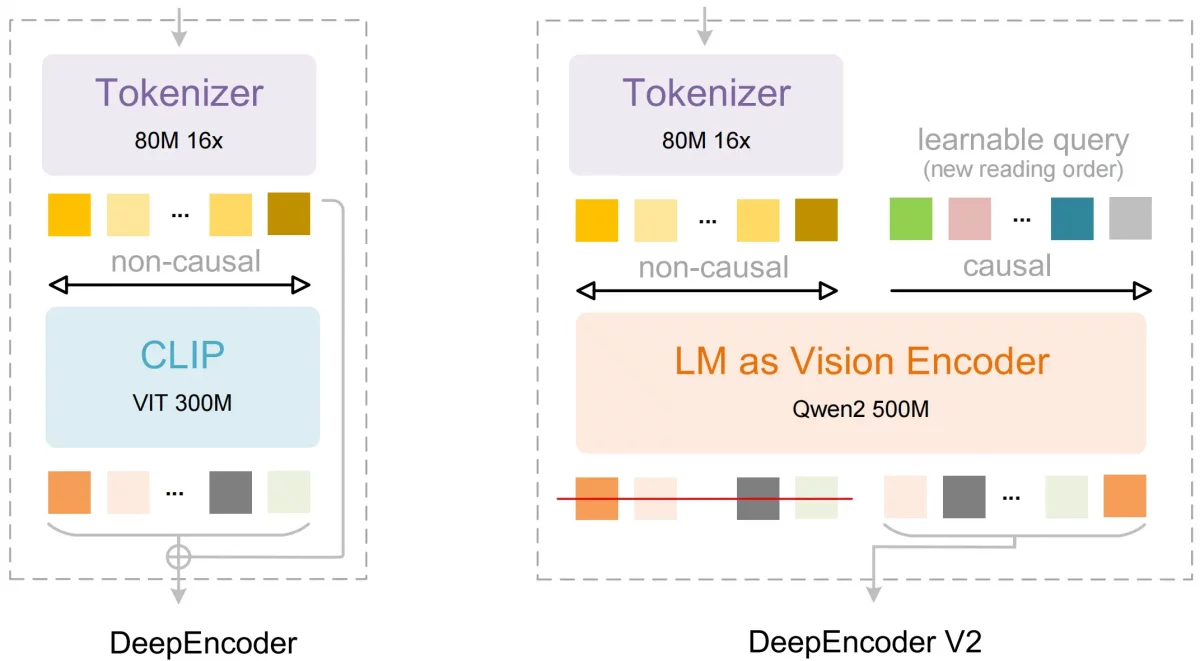
Image Source : DeepSeek-OCR-2@deepseek-ai(GITHUB)
DeepEncoder V2 centrally is based on visual causal flow.
Traditional models read everything at once, but DeepEncoder V2 reads step by step like humans.
One cannot completely understand a sentence until they have read the previous one.
This is to produce a natural progression of reading rather than a two-dimensional scan of an image.
Vision Tokenizer
DeepSeek-OCR 2 retains the identical vision tokenizer design:
- Convolution layer (SAM-style)
- Reduces image resolution by 16x
- Creates small visual tokens in universal context.
This matters because it:
- Keeps computation low
- Supports massive OCR applications.
- Budgets within the budgets of LLM tokens.
The real breakthrough isn’t token compression — it’s what the encoder does after tokenization.
Replacing CLIP with a Language Model Encoder
Visual encoding of CLIP ViT was used in the original DeepSeek-OCR.
CLIP is great at extracting features, and poor at more in-depth reasoning.
DeepSeek-OCR 2 replaces CLIP with Qwen2-0. 5B, transforming a small language model into a vision encoder.
The natural understanding of the language models is:
- Sequence
- Structure
- Logical relationships
- Contextual flow
This essentially transforms the encoder into a visual reasoning engine and not a feature extractor.
Causal Flow Queries: The key Innovation
DeepEncoder V2 adds special learned tokens, known as causal flow queries.
These queries are:
- Just as numerous as visual tokens.
- At the end of the token sequence is appended.
- In charge of restructuring visual information.
Their strict rules of visibility:
- Every query is able to serve all visual tokens.
- It can see previous queries
- It cannot see future queries
This makes the model construct reading order step-at-a-time, as a human may meaningfully scan a page.
Dual Attention Mechanism
DeepEncoder V2 is an amalgamation of two attention styles:
1) Full Image Attention (ViT -style)
The visual tokens come in both directions and offers global understanding of the page.
2) Causal Attention (LLM‑style)
Causal query tokens visit one way and creates logical reading progression.
In simple terms : Visual token refer to what is on the page and the casual token depict the way in which the page must be read .
The tokens of causality are only transmitted to the decoder resulting in a clean and ordered sequence.
Effective Token budget Design
DeepSeek-OCR 2 is quite capable of visual tokens:
- 256 global tokens
- Around 1,120 local crop tokens
It is as fast as DeepSeek-OCR and Gemini, but more accurate without extra cost.
Training Strategy of DeepSeek-OCR 2
The process of training occurs in three phases:
- Encoder pretraining – extract features + reordering of tokens.
- Query refinement with joint retraining – Encoder and decoder learn together.
- Decoder specialization – Encoder frozen, training scaled with more data
This glitzy strategy guarantees:
- Stable learning
- Efficient scaling
- Strong document reasoning
Findings of Deepseek-OCR 2
DeepSeek-OCR 2 is able to achieve on OmniDocBench v.5:
- + 3.73 percent total improvement over DeepSeek-OCR.
- Vigorous improvements in reading-order accuracy.
- Enhanced formulas, table and structured text extraction.
- A smaller number of visual tokens were needed.
This also causes in the practice OCR pipelines:
- Less repetition
- Greater logical consistency.
- Less hallucinations in structured products.
DeepSeek-OCR 2 is not only a research model ― it is almost production-ready.
Why DeepSeek-OCR 2 is more than OCR
The paper makes a bold claim:
The 2-D document comprehension may be subdivided into two causal reasonings:
- Encoder → visual causal reasoning.
- Decoder → causal language generation
This provides the way to new systems where OCR is superseded to:
- Proper understanding of documents.
- Native multimodal encoders
- Coherent vision-language-audio systems.
Conclusion
DeepSeek-OCR2 does not only recognize text in a better way. It learns how to read.
By reducing the encoder to a reasoning module, it:
Fixes the reading order on the source. Alternatives vision and language.
Brings OCR services to close to document and intelligence.
DeepSeek-OCR 2: This is a big advancement in understanding semantics of documents.
“Ready for intelligent AI powered Commerce? Your journey starts at Webkul.“

Be the first to comment.