Qwen3-TTS: Multilingual, Real-Time Speech AI
Text-to-speech technology has improved fast, but many solutions still struggle in real-world use.
The main problems are few languages, slow or flat speech, and weak control over voice or emotion.
It addresses all these problems in one single design.
This model is a next-generation, end-to-end TTS model built around three main goals:
It works in many languages, speaks quickly, and lets you change the voice easily. It’s simple and fast to use.
Dialect and Voice Awareness Multilingual Support
Qwen3-TTS can talk in 10 languages.
Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, and Italian.
These languages can be used for reading text, voice assistants, dubbing, and voice chatbots.
The key feature of this models is the deep knowledge of the language.
The model understands dialects, accents, age, gender, and speaking styles. This helps it produce natural speech that fits different regions and cultures.
It uses one model for all languages and accents. This makes it much easier to deploy across many languages at scale.
Context-Sensitive Speech Generation in Qwen3 TTS
Traditional TTS synthesizers primarily convert text to audio. It goes a step further to analyze intent, semantics and emotional circumstances.
It automatically adjusts tone, speaking speed, emotion, rhythm, and flow based on the text and simple user instructions.
Users can make speech calm, excited, or confident
This helps the speech sound natural and stay clear, even if the text has mistakes.
Speech Tokenization: The Innovation
This model is based on a tokenizer which is Qwen3-TTS-Tokenizer-12Hz.
It turns raw audio into small codes and then rebuilds them into high-quality speech.
The design provides audio compression without loss of detailed semantic and acoustic content.
It also keeps emotion, speaker identity, and background context, unlike older tokenizers.
This lets Qwen3-TTS make clear, natural speech with a simple design.
Complete End-to-End Architecture of Qwen3 TTS

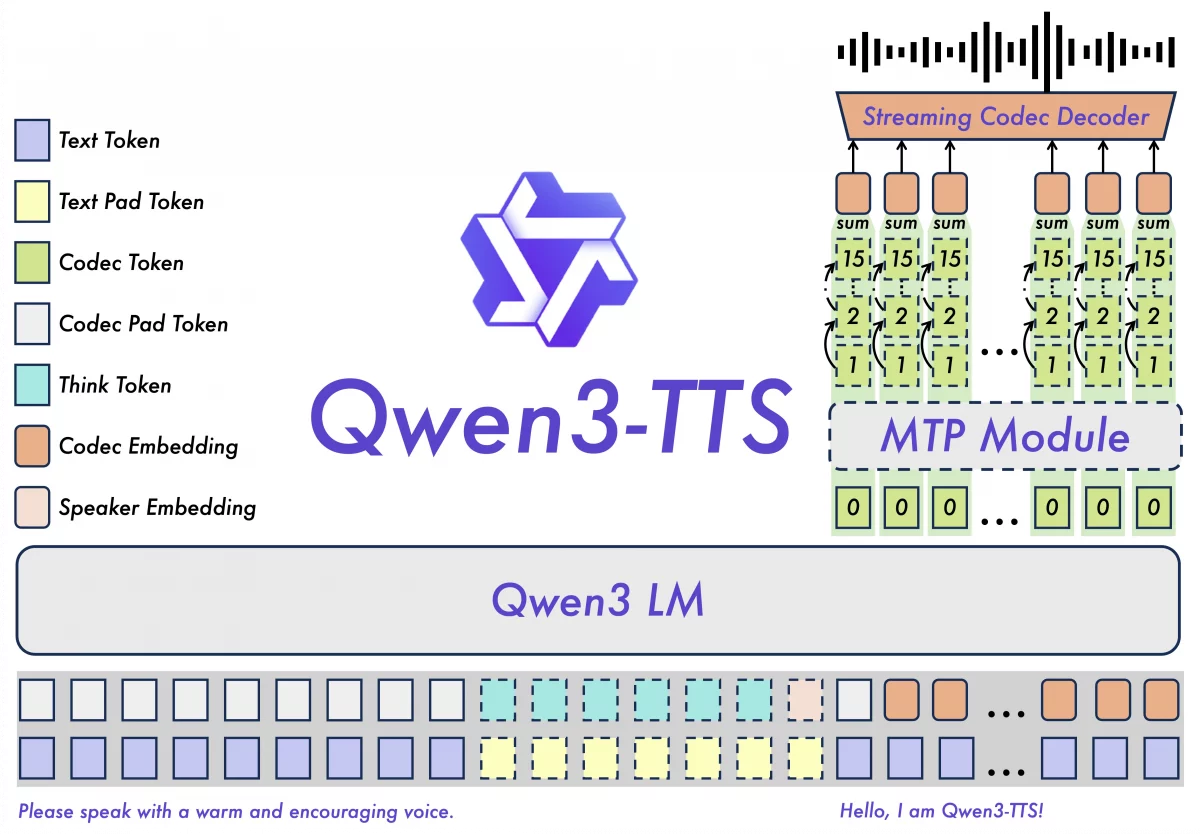
Image Source : qwen3tts@qwen.ai
Most TTS systems have many steps, like text processing and speech modeling. Each stage can add errors and lose information.
Qwen3-TTS avoids this complexity by using a discrete multi-codebook language model. It can handle the entire speech process in one system.
Using one stage reduces mistakes, works better, and is easier to use and maintain.
This all-in-one design is easy to use for streaming, voice cloning, and voice design.
Streaming Performance at Ultra-low Latency
One of the major characteristics of this model is real-time streaming system.
It can handle both live and recorded speech with one model.
key perfomance includes, it can start speaking from a single character, with only 97 ms delay.
Voice assistants, live agents, and chatbots need quick answers.
Even small delays can hurt the user experience.
Instruction Voice and Style Control in Qwen3 TTS
This model lets users control the voice with easy text commands.
It can adjust timbre, emotion, rhythm, and flow by closely linking the text to the speech it generates.
The workflow is simple: choose the voice you want, and the model will create it.
This helps creators, narrators, and AI talk naturally.
Qwen3 TTS model Variations
It comes in several models. They all use the same core design but are set up for different uses
Tokenizer
Qwen3 TCP 12Hz TTS -12Hz speech encoding and decoding core shared by all models.
Model Lineup
1) Qwen3-TTS-12Hz-1.7B-VoiceDesign is a version that can create voices based on written descriptions. Enables complete control of instruction and streaming of all supported languages.
2) Qwen3-TTS-12Hz-1.7B-CustomVoice gives clear voices for different ages, genders, and dialects.
3) Qwen3-TTS-12Hz-1.7B-Base makes 3-second time cloning of voice fast and a base to use to fine-tune.
4) Qwen3-TTS-12Hz-0.6B-CustomVoice is a small, deployment-friendly model which can use high-end timbres.
5) Qwen3-TTS-12Hz-0.6B-Base is a small model for lightweight voice cloning and personalization.
Every model has ten languages and most of them have the streaming generation.
Why Qwen3‑TTS Is Important
Qwen3 -TTS is not just a TTS model. It is a step towards integrated, instruction-conscious, real-time speech-generation.
This model solves many long-standing TTS problems with a unified approach.
It has clear speech, works fast, and lets you control the voice easily.
App makers, voice creators, and real-time voice apps all find Qwen3-TTS useful and easy to use.
The model’s weights are free and open, ready for anyone to experiment with or deploy.
“For more recent AI updates and Advancements, visit Webkul !”