GLM-5: Frontier Leap of Vibe Coding to Agentic Engineering
Zhipu AI announced GLM-5 on February 11, 2026. The company has ties to Tsinghua University.
It is an open-weights model built for complex tasks. It helps developers and engineers build AI agents that can handle long and difficult work.
In contrast to the incremental releases in the GLM-4 series (e.g. 4.5, 4.6, and 4.7), GLM-5 is a major architectural and scale leap.
It is made for real-world tasks and step-by-step automation, not just quick prompts. Agents can plan, act, fix errors, and run long tasks.
Major Technical specifications and innovations in GLM-5
GLM-5 is a Mixture-of-experts (MOE) model that has:
- 744B total parameters with 40B used at once, compared to 355B total and 32B active in GLM-4.5.
- Pre-training data: Increased to 28.5T tokens (23T).
- Context window: 200K–205K tokens, with strong long-context retention.
- Max output: Up to 128K tokens.
- DeepSeek Sparse Attention (DSA): It lowers the cost to run the model while still working well with long inputs.
The team created a new training system called SLIME. It helps improve the model faster after training.
This training helps the model turn its basic skills into strong performance for AI agent tasks.
The full model uses BF16 precision and is very large (about 1.5TB to download). Smaller compressed versions are also available and need much less space.
It uses the MIT license and is fully open-source on Hugging Face and ModelScope. You can run it on platforms like Ollama, Together AI, and NVIDIA NIM.
The model was trained and run on Chinese hardware, such as Huawei Ascend chips and the MindSpore framework. This helps reduce the need for foreign technology.
Performance Highlights and Benchmarks of GLM-5

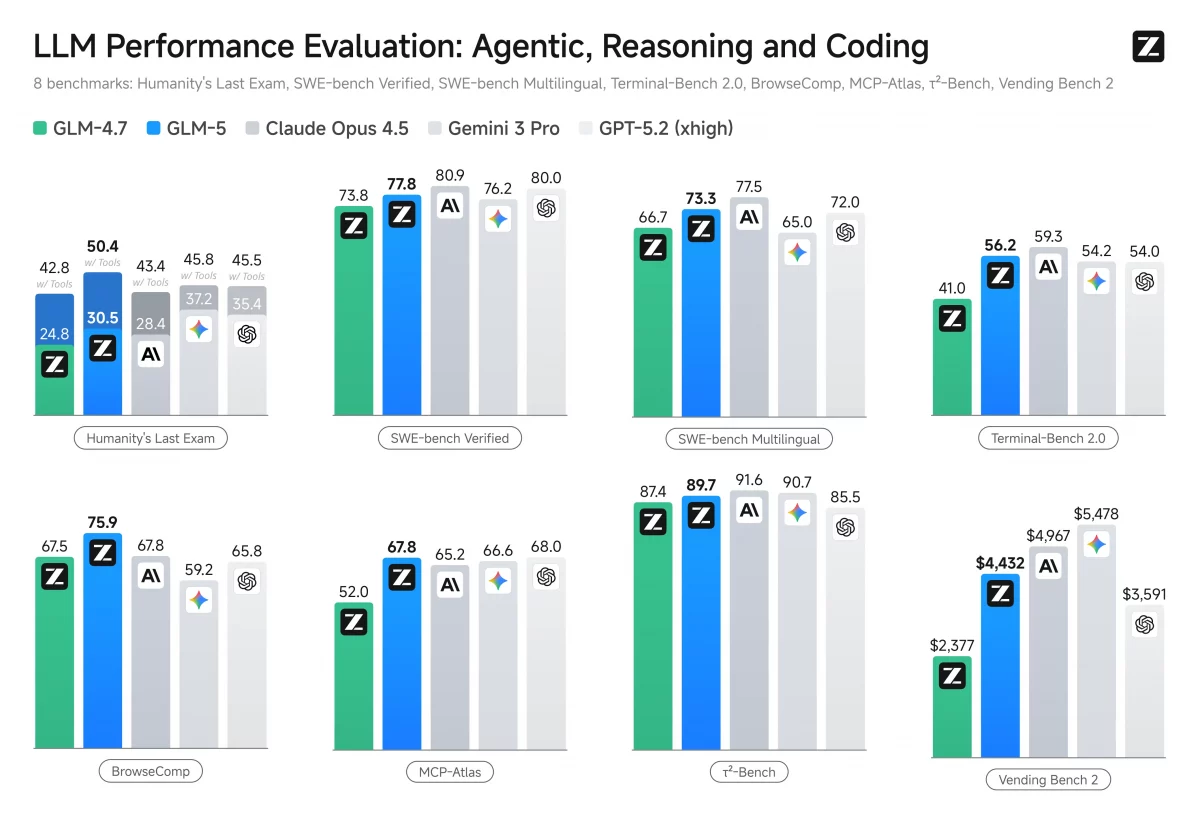
GLM-5 performs better (among open-weights models) in reasoning, coding and agentic tasks.
It performs much better than GLM-4.7 and is close to top closed-source models like Claude Opus from Anthropic.
Key reported scores :
- The Last Exam of Humanity (HLE): 50.4% (using tools; +7.6 percent better in particular evals).
- SWE-bench Verified: ~77.8% (good coding/systems engineering performance, nearly best closed models).
- GPQA-Diamond: 86.0%.
- AIME 2026: 92.7%.
- BrowseComp: 75.9% (+8.4%).
- Terminal-Bench-2.0: 61.1% (+28.3%).
- Good performances on MATH, MMLU-Pro and IFEval and on internal suites such as CC-Bench-V2.
It ranks very high among open-source models for agent tasks and long problems. It also reduces false answers by up to 56% compared to GLM-4.7.
In Artificial Analysis Intelligence Index, it also scored the first open-weights position (score of about 50, which was 42 in GLM-4.7).
Early users praise its coding skills and reliability for AI agents.
Some say it can be slower or give longer answers than some closed models.
Competitor Analysis
1. Vs. GLM-5 and Sonnet variants are much cheaper open models and perform well on coding and agent tests like SWE-bench.
In API systems, some analyses refer to it as having been Opus 20 percent of the price.
2. Vs. GPT-4o: Greater context, better on recent agentic/reasoning evals, and less costly in most instances. GPT-4o is more ancient (2024) and has a smaller context (128K).
3. Vs. other open models (DeepSeek V3, Qwen series, etc.): GLM-5 sets a new high bar for scale + agentic focus among openly available weights.
The API price is competitive, about $1 per million input tokens and $3.20 per million output tokens, which is cheaper than many top closed models.
Soon after, a faster and cheaper version called GLM-5-Turbo was released for agent workflows. It is not fully open-source.
Why Agentic Engineering Matters
The philosophy shift is depicted in the tagline: From Vibe Coding to Agentic Engineering.
The previous models were good at quick and creative vibe-based coding. GLM-5 focuses on long-standing and reliable agents which can:
- Soft engineering Multi-file.
- The use of tools and long-chain performance.
- Filthy systems planning and debugging.
- OpenClaw persistent automation integrations.
This follows the industry trend of building AI agents that can design and manage large systems, not just write code.
Availability and How to Try It
- Hugging Face: zai-org/GLM-5 (weights + code).
- Ollama: run glm-5/ollama run glm-5.
- API: Using Z.human, Together AI, OpenRouter and more.
- Local programs: Unsloth, llama.cpp, or SGLang to run program inference. The full model needs strong hardware and about 1.65TB of disk space. Smaller versions can run on lighter systems.
Final Thoughts
GLM-5 is a milestone that is striking, not only to Z.ain or the domestic AI ecosystem of China, but to the entire open-source community in the world.
It offers strong AI agent abilities with an MIT license. It also uses new ideas like DSA and advanced RL to work more efficiently.
This makes powerful Artifical Intelligence tools easier for more people to use, without paying for costly APIs.
GLM-5 is worth trying, whether you are building agents, or working with large codebases, or even with local LLM.
It is an indication that open-weights models are closing the gap with closed giants at an unbelievable rate.
The competition of more competent, effective, and independent AI increases.
Want to Build AI-powered solutions visit Webkul!