GLM-4.7 Flash : Top Mid-Size Open Model
The open-source LLM is a rapidly evolving field, with most of the models being either large, costly, or small and restricted.
It is in the middle of GLM-4.7-Flash, and that is why it is important.
Released by Zhipu provides good reasoning and coding capabilities without using many computations.
It generally performs better than models such as GPT-OSS-20B in most real world tasks and is also generally easier and faster to deploy.
What Exactly Is GLM-4.7 Flash?
It is a middle-size Mixture-of-Experts (MoE) model.
Total parameters: ~30 B Active parameters per unit B:
3B Architecture: MoE to work,
not to gnash.
It is an inference time that only a little bit of the model is operational.
This allows it to be significantly faster and cheaper to execute than similarly sized dense models, and retains a high level of reasoning capability.
This design option is the primary reason why Flash works this well despite its size.
Why GLM-4.7 Flash Outperforms GPT-OSS-20B

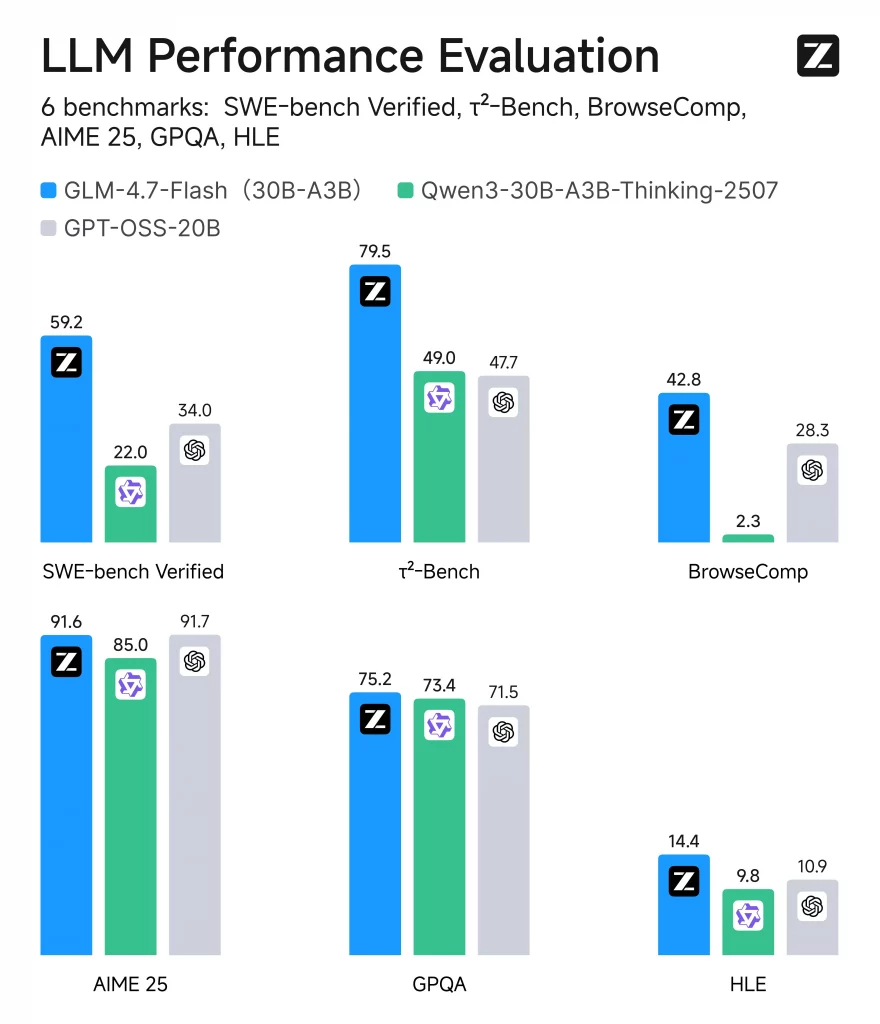
Image Source : glm-4.7@docs.z.ai
GPT-OSS-20B on paper looks competitive. Practically, GLM-4.7 Flash always performs better on those aspects that are important to the developers.
1) Better Reasoning per Token
Multi-step reasoning tasks are solved more efficiently by Flash. It has fewer logical jumps and longer processing of chains of thoughts as compared to GPT -OSS-20B.
2) Greater Coding Performance
This model is significantly more competitive in coding, such as in bug fixing, refactoring, and repo-level understanding. It knows intent more, and writes a useful code the first time around.
3) Long Context Advantage
Flash has extremely large context windows (up to maybe 200K tokens). GPT‑OSS‑20B struggles here. That matters for:
- Large codebases
- Long documents
- Agent workflows
4) More Efficient Deployment
Although Flash has more total parameters, it is often less expensive and faster to execute because it uses only a small, specialized subset at a given time.
Where GLM-4.7 Flash Truly Excels
This model is particularly suitable in:
- Coding assistants
- AI agents and tool calling
- Long‑document analysis
- Thinking and planning assignments
- Local or semi-local implementation.
It is like it is designed to builders not to demos.
What GLM-4.7 Flash Is Not
It would not be a flagship to the largest closed models.
Even when you require the highest possible accuracy on very complicated mathematics or on niche reasoning large models beat the day. But that’s not the point.
Conclusion
GLM-4.7 Flash is one of the finest mid-size open models that are currently in the market.
It performs better and more comfortably in reasoning, coding and long context tasks than GPT-OSS-20B, and is simpler to cut in deployment.
This model is very reasonable given that you are creating real systems, agents, developer tooling, or internal copilots.
It does not make a splash, it does not stick out like a sore thumb, it is simply a very well-engineered garment.
That is the reason why GLM -4.7 Flash is special.
For more AI Advancements visits webkul !!